
It’s a fact that, GPUs more powerful than CPUs. The question is Why are GPUs more powerful than CPUs?
Graphics processing units (GPUs) have become increasingly popular over the past couple of decades, especially for highly parallel computational tasks like graphics rendering, deep learning, and scientific computing.
GPUs can offer much higher performance than central processing units (CPUs) on certain workloads by leveraging their massively parallel architecture.
This article will provide an in-depth explanation of why GPUs are able to achieve much greater throughput for many algorithms.
Why GPU is Faster Than CPU
In this article we’ll go through different facts to find out why gpu computing is faster than cpu.
GPU Architecture
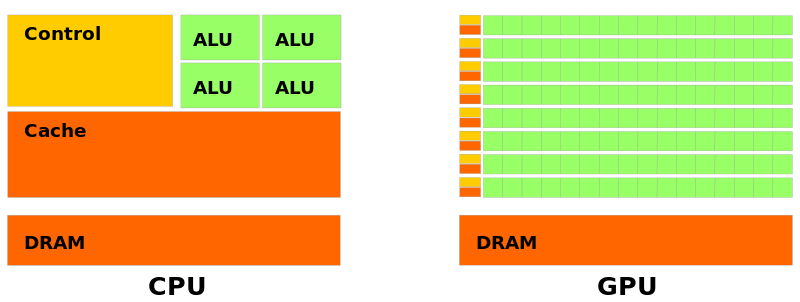
The key difference between GPU and CPU architectures is that GPUs are designed for data parallelism while CPUs are designed for sequential serial processing. GPUs have hundreds or thousands of smaller, simpler cores while CPUs have a few large complex cores with lots of cache memory.
GPU cores are also optimized for performing similar operations on multiple data elements simultaneously. For example, adding two vectors of numbers is an easily parallelizable operation – each core can independently add one element from each vector. The results can then be combined once all the parallel computations have completed.
In contrast, CPU cores are optimized for low latency fetching and decoding of sequential instructions. Operations often depend on previous computations so CPU cores utilize techniques like branch prediction and speculative execution to minimize stalls. Complex cache systems keep frequently used data close to the cores.
Memory Architecture
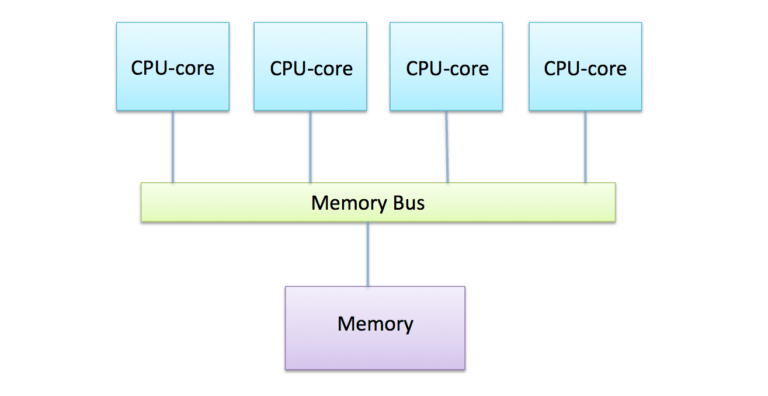
In addition to their computational differences, GPUs also utilize specialized high-bandwidth memory architectures to feed data to all the cores. GPUs typically incorporate GDDR or HBM memory which offers order of magnitude higher bandwidth than standard DDR RAM in CPUs.
Data for GPU processing is transferred into this specialized memory to minimize access latency during parallel computations. The memory is segmented so concurrent access from different cores can be performed for maximum throughput.
In comparison, CPU memory systems are highly optimized for low latency access to cached data. There is less emphasis on total bandwidth which reduces effectiveness for data parallel workloads.
Parallelism
The combination of specialized cores and memory enables GPUs to exploit data parallelism to a much greater degree than CPUs. For tasks like graphics rendering, the same shader programs can be run in parallel on many vertices or pixels.
Modern GPUs contain thousands of cores while high-end CPUs max out at around 30 cores. With more cores, GPUs can process data in wider parallel with higher arithmetic intensity. The GPU cores can collectively achieve 100x or more throughput than a CPU for parallel workloads.
In contrast, Amdahl’s law means CPUs are limited in how much parallel speedup they can attain for an algorithm. Even with 30 cores, real-world speedups are bounded to 10x or less due to sequential portions and communications. GPUs can achieve almost perfect parallel speedups thanks to their massively parallel architecture.
Just-in-Time Compilation
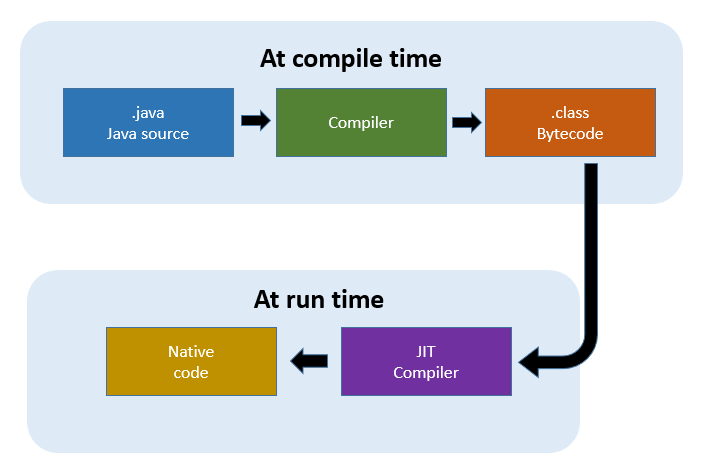
Another advantage of GPUs is just-in-time (JIT) compilation which reduces overhead for dispatching parallel workloads. GPU drivers and runtimes feature JIT compilation to convert high-level shader code into optimized device instructions right before execution.
This provides flexibility for programmers while avoiding the traditional offline compilation step required for CPUs. JIT also enables optimizations based on runtime information. The combined effect reduces GPU overhead to nearly zero.
In comparison, CPUs must stick to pre-compiled machine code and cannot adaptively recompile based on runtime behavior. There is inherently higher dispatch overhead for CPUs along with less flexibility.
Programming Model
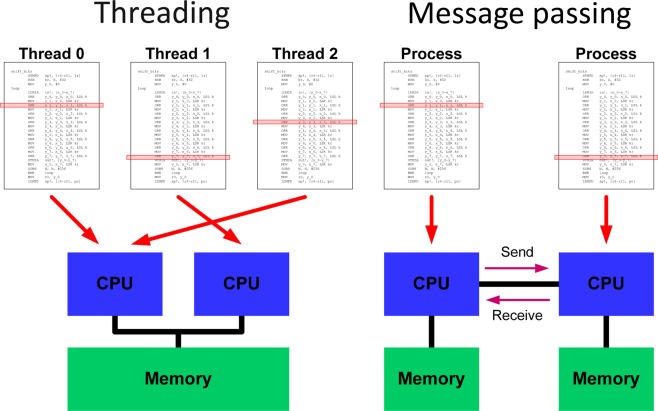
GPUs also present a much more abstract parallel programming model compared to CPUs. Developers can write parallel code at a high level without worrying about low-level threading, synchronization, and communication.
CUDA and OpenCL provide C/C++ abstractions where code focuses on declaring parallel computations across abstract threads. The messy coordination details are handled invisibly under the hood.
In contrast, CPU parallelism requires directly working with threads using libraries like OpenMP. There is significant extra complexity around thread management, locks, and avoidance of race conditions. This makes it much harder to think about parallelism from a high level.
Workloads
The advantages of GPU architecture manifest in certain workloads with abundant data parallelism. Graphics workloads are an obvious example – vertices, pixels, and textures can all be processed in parallel in graphics pipelines. GPUs now render nearly all modern video game graphics thanks to custom units for geometry, shading, texturing, rasterization, and video encoding.
In machine learning, GPUs excel at tensor and matrix math required during neural network training. Matrix multiplication involves significant parallelism that GPUs can optimize for high throughput. Training large deep learning models on GPUs can be orders of magnitude faster compared to CPUs.
For scientific computing, algorithms in fields like physics, chemistry, and engineering often rely on linear algebra and simulation. SIMD parallelism applies perfectly to these numeric-heavy workloads. Problems like fluid dynamics and protein folding commonly leverage GPU acceleration.
GPU vs CPU Performance Comparison
Graphics processing units (GPUs) and central processing units (CPUs) take markedly different approaches to computational problems. GPUs emphasize massively parallel architectures while CPUs focus on serialized operations and sophisticated caching systems.
These architectural differences lead to huge performance gaps on certain workloads.
This article will provide a comprehensive technical comparison between GPUs and CPUs in areas like architecture, memory, programming, and representative workloads.
Architectural Differences
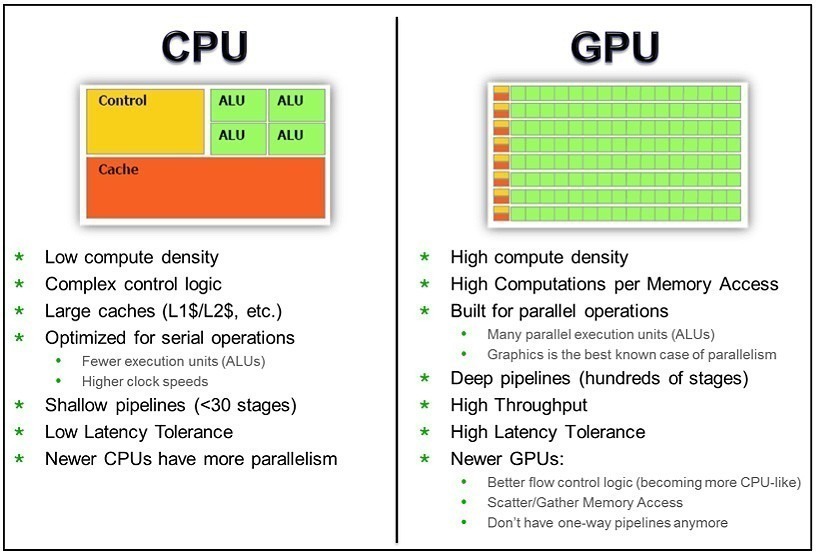
The most fundamental difference between GPU and CPU architecture is the number of cores. High-end GPUs today contain thousands of simple cores designed for data parallel execution. Nvidia’s A100 GPU has over 50 billion transistors powering nearly 7000 CUDA cores. In comparison, even expensive server CPUs max out at around 64 complex cores.
This massive parallelism allows GPU cores to collectively process data and execute programs with immense throughput. A core simplistic design minimizes chip space and power requirements. GPU cores also tend to have a very high arithmetic intensity as they are optimized for floating point matrix and vector operations.
In contrast, CPU cores are large and complex, featuring deep pipelines and sizable cache memories. Workloads involve fetching instructions, decoding them, managing execution, and handling dependencies. CPU cores are designed for minimizing latency and maximizing responsiveness for these serialized operations. Techniques like branch prediction, out-of-order execution, and speculative execution help overcome stall cycles.
Memory Architectures
In addition to computational differences, GPUs also employ specialized memory architectures and bandwidths. Consumer GPUs often use GDDR memory delivering over 500 GB/s bandwidth. High-end GPUs employ stacked memory like HBM delivering up to 3 TB/s bandwidth.
This compares to around 60 GB/s bandwidth for the most advanced DDR5 RAM used in CPUs. The ultra-wide bus and throughput minimizes data access latency during parallel execution on GPUs.
CPU memory is optimized differently, with small low-latency caches layered hierarchically to store frequently used data as close to the cores as possible. There is less emphasis on high bandwidth.
Parallel Programming Model
GPU programming languages like CUDA expose the massively parallel architecture through a high-level abstraction. The code focuses on declaring parallel sections which run on many virtual threads simultaneously.
Developers do not have to coordinate actual CPU threads and cores explicitly. Management like load balancing and communication happens under the hood. This provides enormous productivity benefits.
In contrast, CPU parallelism involves directly working at the thread level with libraries like OpenMP. Developers have to manually divide work between threads, accommodate race conditions and locks, and manage non-parallelizable portions with traditional code.
Just-in-Time Compilation
An important software advantage for GPUs is just-in-time (JIT) compilation. Instead of offline ahead-of-time compilation, GPU drivers JIT compile and optimize kernel code at runtime right before execution.
This dynamic approach allows for greater flexibility – programs can adapt based on runtime information. It also minimizes dispatch overhead. Once launched, thousands of GPU threads run with little overhead.
CPUs have fixed machine code output from offline compilers. There is no ability to recompile adaptively at runtime. CPU threading has higher dispatch overhead as well.
Ideal Workloads
The advantages of GPU architecture manifest most strongly on workloads with abundant parallelism. Computer graphics is the most obvious example. The algorithms map perfectly to the massively parallel architecture.
Vertices, textures, pixels can all be processed independently in parallel. GPUs now render graphics for virtually all video games thanks to special units for geometry shading, texture mapping, rasterization and other stages. A GPU with 5000 cores can process pixels 500x faster than a CPU.
Neural network training for deep learning involves enormous amounts of matrix multiplication. GPUs can parallelize these linear algebra operations across thousands of cores leading to order of magnitude training speedups over even the fastest CPUs.
Many numerical simulations are also “embarrassingly parallel”. Problems in disciplines like computational fluid dynamics, climate modeling, and molecular dynamics require running the same set of formulas across large datasets. With enough data parallelism, GPUs achieve near perfect utilization and throughput.
GPUs and CPUs take very different architectural approaches optimized for different classes of algorithms. For parallelizable problems with abundant arithmetic operations, GPUs vastly outperform CPUs thanks to their many simple cores, high memory bandwidth, and flexible programming. On sequential problems with more complex logic, CPUs maintain the advantage. Understanding these fundamental differences allows developers to select the right processor for their workloads.
Conclusion
GPUs vs CPUs represents a fundamental divergence in processor design and capability. GPUs emphasize massive parallelism, simple control flow, and high arithmetic intensity. Their thousands of cores and tremendous memory bandwidth enable unprecedented throughput on parallelizable loads like graphics, AI, and scientific computing.
CPUs take the opposite approach – fewer cores, complex control logic, and sophisticated caching to minimize latency. This allows CPUs to excel at reactive responsiveness, user interactions, business logic, and dynamic workloads.
There is no universally superior architecture. GPUs excel where parallel scalability is paramount. CPUs shine where real-time latency and sequential logic dominates. The processors have vastly different performance profiles on opposite classes of algorithms.
Understanding these complementary strengths is vital for developers. The choice of CPU vs GPU can mean the difference between a task taking minutes versus hours. By judiciously leveraging both processing paradigms, modern computing systems can deliver the best of both worlds – massive parallel throughput along with responsive interactivity.
As data and complexity continue exploding, heterogeneous systems marrying the benefits of specialized CPUs and GPUs will only grow in importance. Architectural innovation and software advances will further expand the capabilities of both paradigms. But the core divergent philosophies underpinning CPUs and GPUs look set to remain industry cornerstones for the foreseeable future.
FAQs
No, GPUs are generally much faster than CPUs for parallelizable workloads like graphics, deep learning, and scientific computing. GPUs have thousands of cores optimized for parallel processing while CPUs max out around 30 cores.
GPUs are better than CPUs for parallel workloads because of their massively parallel architecture, high-bandwidth memory, just-in-time compilation, and abstract programming model. All these advantages allow GPUs to exploit data parallelism to achieve higher throughput.
GPUs are better for AI because neural network training involves large amounts of matrix math and parallel computations. Thousands of GPU cores can process the linear algebra operations simultaneously, accelerating deep learning training by orders of magnitude over CPUs.
Author
-
by
-
